Diverse Image-to-Image Translation via Disentangled Representations (DRIT)
Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Singh, Ming-Hsuan Yang (ECCV2018)
The original paper is here.
Official Github Repo is here under Python3.5-3.6, Pytorch0.4.0 and CUDA9
My modified version is here, compatibale under Python3.7.10, Pytorch1.8.0 and CUDA11.0
Objectives
- Aim to disentangle content and attribute from images
- Use the disentangled representation for producing diverse outputs
Target
- Content space is shared among domains
- Attribute space encodes intra-domain variations
To make content latent zcx and zcy share a same content space C:
- Share weight between the last layer of Ecx and Ecy and first layer of Gx and Gy so the higher level features will be mapped to same space (but still cannot guarantee the same content representations encode the same information for both domains
- Use content discriminator Dc for adversarial training
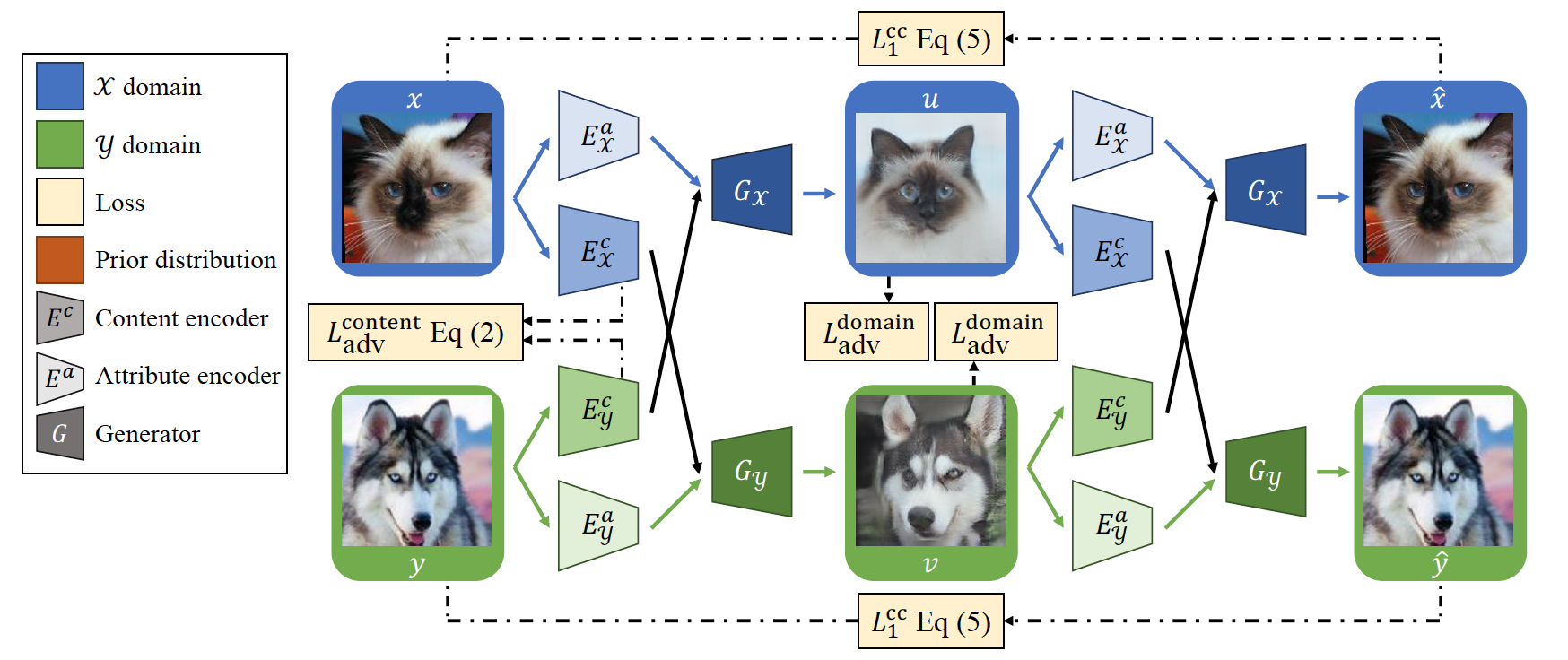
Loss functions
Content adversarial loss:
- To encourage content latent from x and y share a same content space C
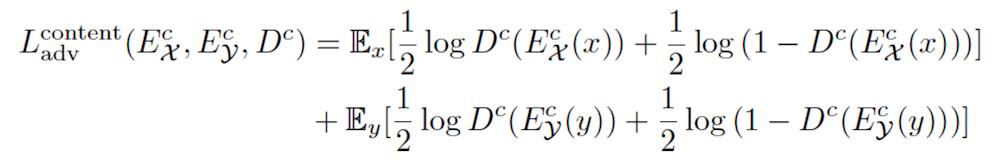
Cross-cycle consistency loss
- Forward translation and backward translation
- To encourage the reconstruction after two Image-to-Image translations
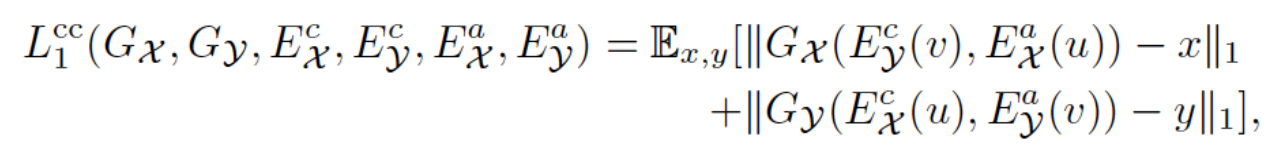
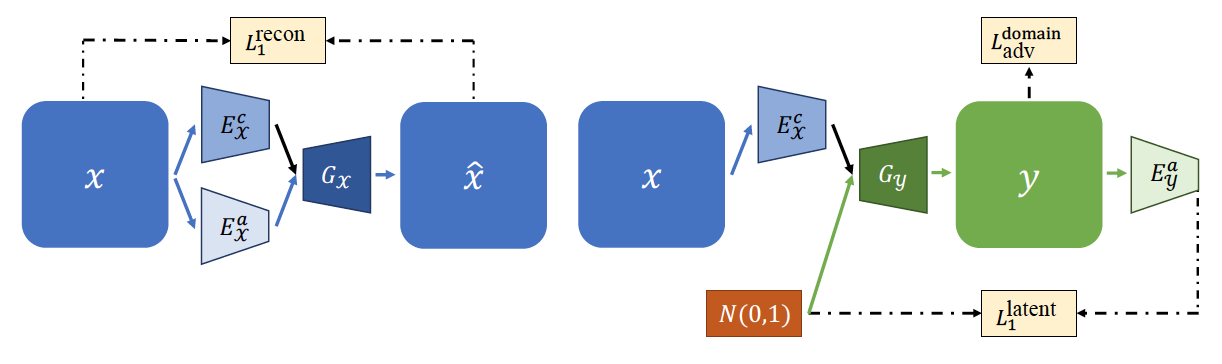
Self-reconstruction loss:
- To facilitate the training of encoder and decoder in addition to the cross-cycle reconstruction
Domain adversarial loss:
- Domain discriminator Dx and Dy attempt to discriminate between real images and generated images in each domain
- To encourage Gx and Gy to generate realistic images
KL loss:
- To encourage the attribute representation to be close to a prior Gaussian distribution
- For easy sampling at test time
Latent regression loss:
- To encourage the invertible mapping between the image and the attribute latent space
- Attempt to reconstruct the attribute representation drawn from the prior Gaussian distribution
Full objective function: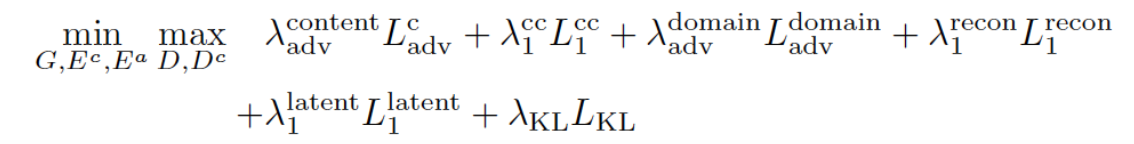
Code implementation
I have summarised the architecture of the official implementation together with the key variable names in following diagram.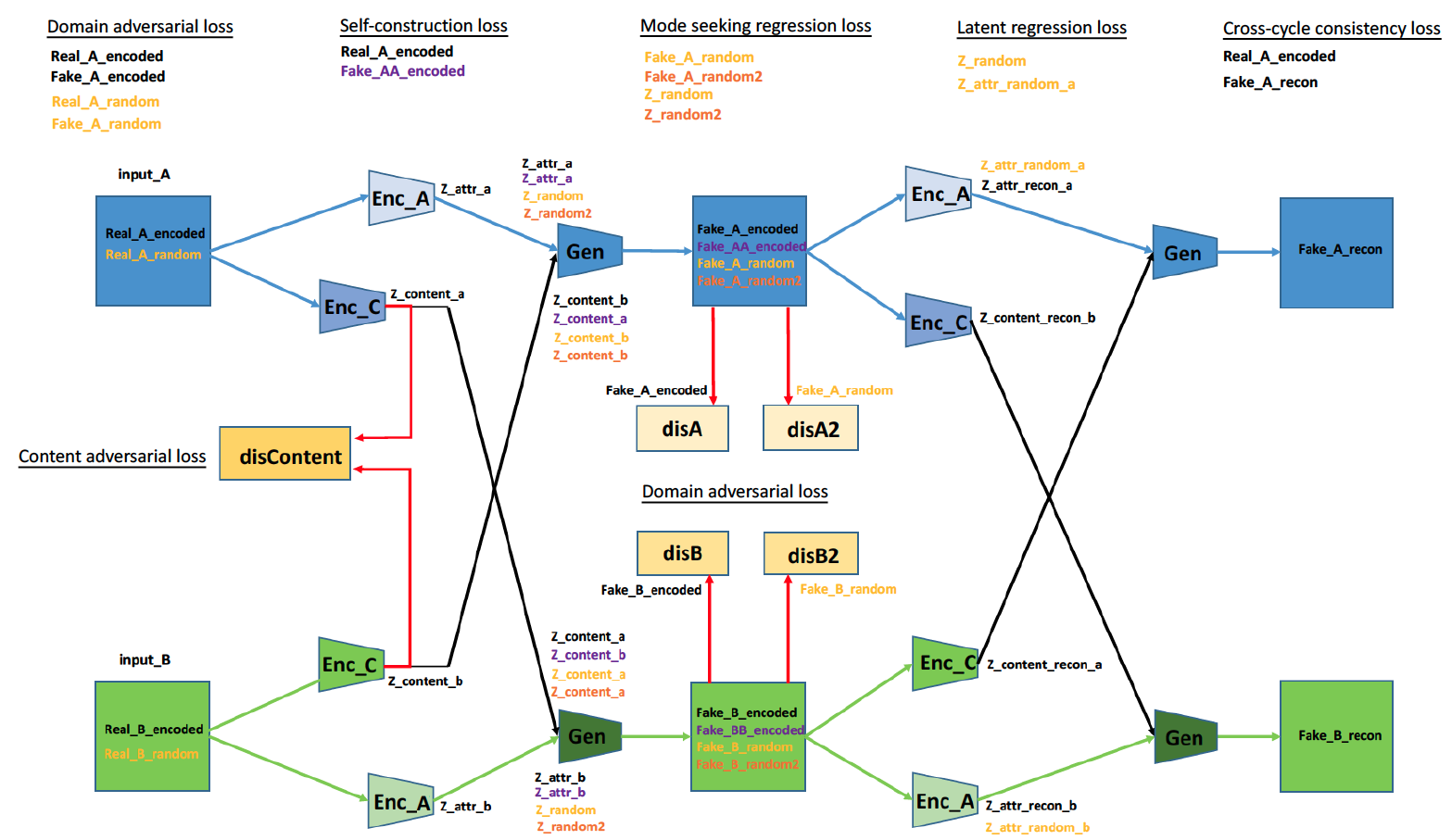
The official released code is implemented under old Pytorch version and CUDA9, so if your GPU does not support CUDA9 and have no choice but to run using later Pytorch version, you most probably will encounter some Runtime Error related to in-place operations. The reason is that in old Pytorch versions (at least up to 0.4.0), node version mismatch between its forward and backward is not detected even though this should not be allowed. In later Pytorch version this issue is fixed and it will produce error explicitly.
If we look at the original code in model.py, we can see that the second backward operation is performed straightly after the first backward and step operation. So when self.backward_G_alone() is performed it will detect that nodes along its propagation path have different versions compared to that in forward propagation time and in-place operation error pops up here.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def update_EG(self):
# update G, Ec, Ea
self.enc_c_opt.zero_grad()
self.enc_a_opt.zero_grad()
self.gen_opt.zero_grad()
self.backward_EG() # first backward to obtain gradient values
self.enc_c_opt.step() # update node values
self.enc_a_opt.step() # update node values
self.gen_opt.step() # update node values
# update G, Ec
self.enc_c_opt.zero_grad()
self.gen_opt.zero_grad()
self.backward_G_alone() # another backward to obtain gradient values
self.enc_c_opt.step()
self.gen_opt.step()
The solution here is also simple, just bring the self.backward_G_alone() call before the step operation. You can refer to my folked repo with modified code here also.1
2
3
4
5
6
7
8
9
10def update_EG(self):
# update G, Ec, Ea
self.enc_c_opt.zero_grad()
self.enc_a_opt.zero_grad()
self.gen_opt.zero_grad()
self.backward_EG()
self.backward_G_alone() # backward_G_alone here to accumulate gradient together before update
self.enc_c_opt.step()
self.enc_a_opt.step()
self.gen_opt.step()
Results after 1200 epoches using cat2dog dataset: